 hashart called
hashart called
 element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
hashart called
element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
hashart called
element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. Informally, this may be thought of as, "What happens next depends only on the state of affairs now.”
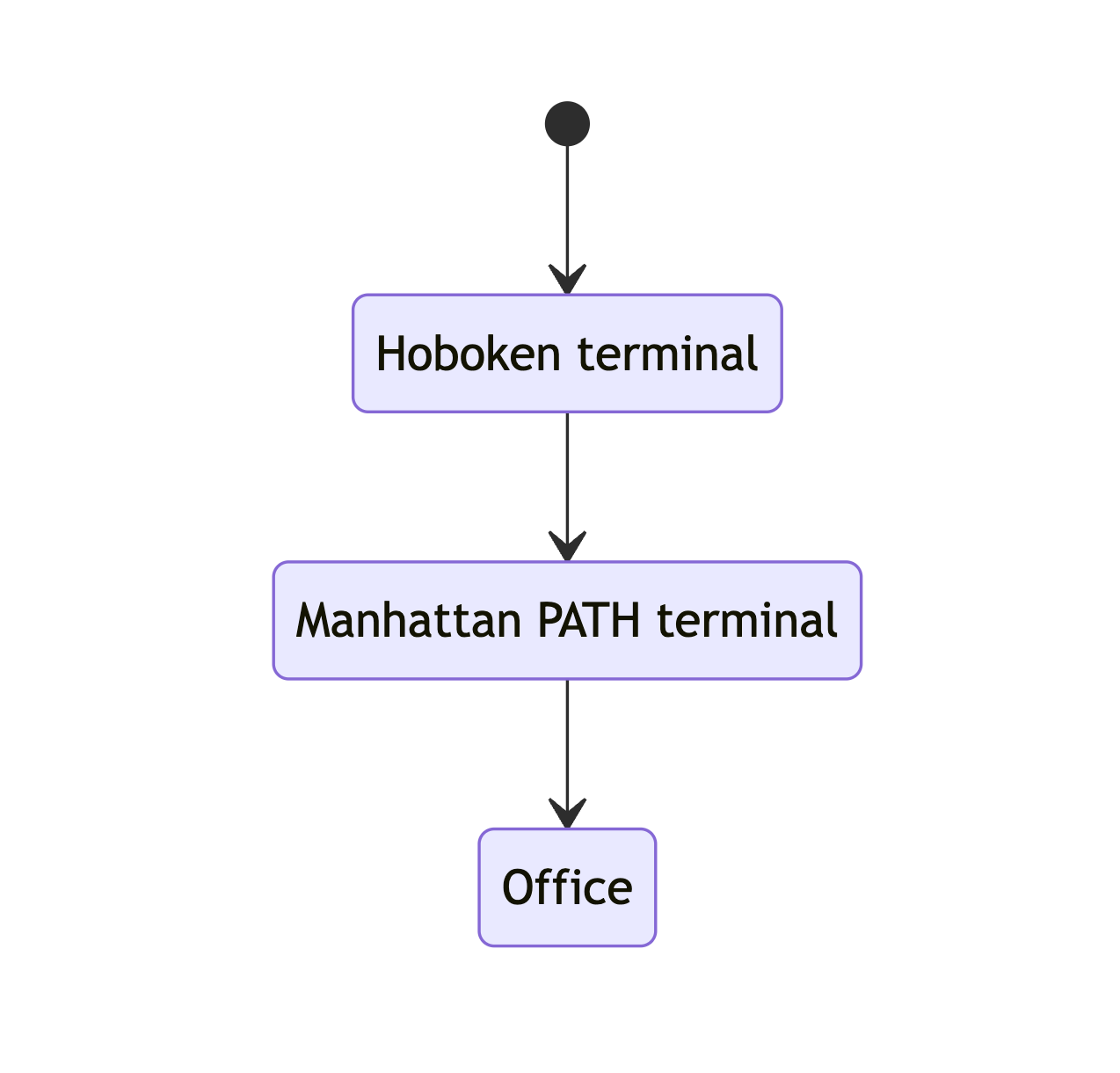

 . We’ll add these states and, importantly, the probabilities of each route.
. We’ll add these states and, importantly, the probabilities of each route.
 end state. Once I’m at Hoboken PATH my commute is pretty much over.
end state. Once I’m at Hoboken PATH my commute is pretty much over.
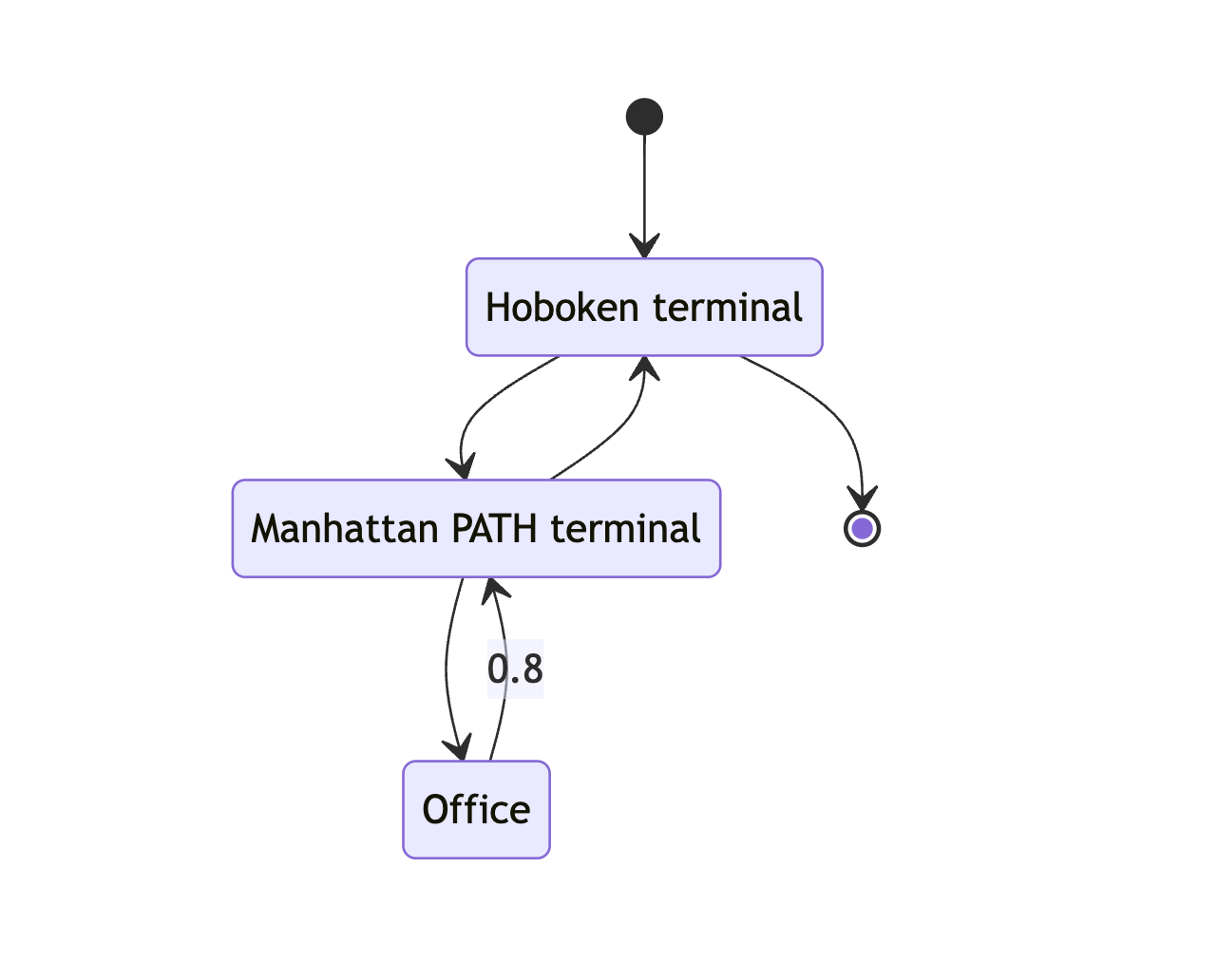 commute.
commute.
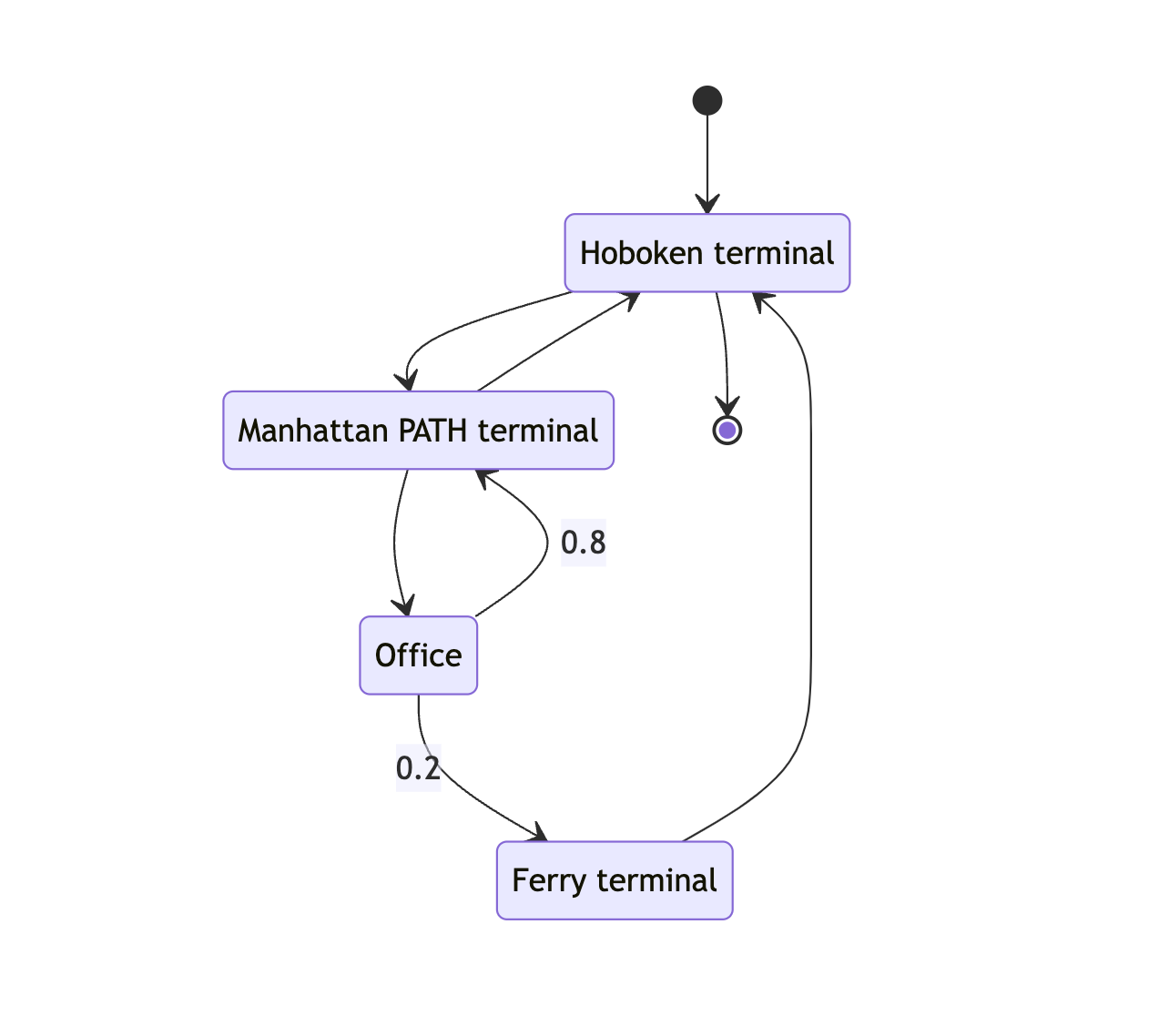
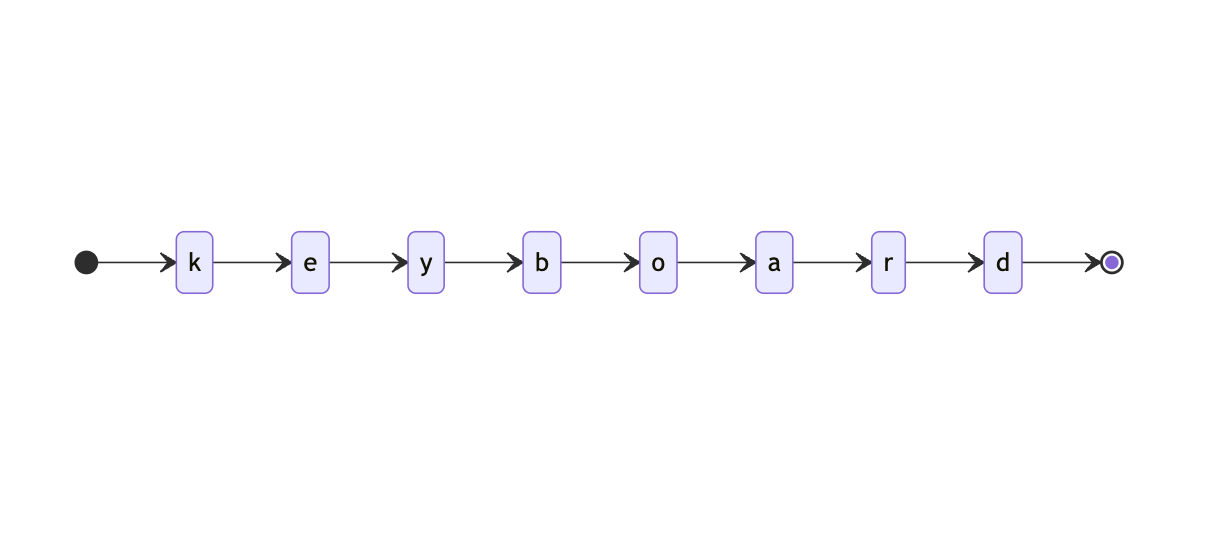
 → Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →  → Hoboken terminal → Manhattan PATH → Office → Ferry → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Hoboken terminal → Manhattan PATH → Hoboken terminal → …
→ Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Office → Ferry → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Hoboken terminal → Manhattan PATH → Hoboken terminal → …
→ Hoboken terminal →
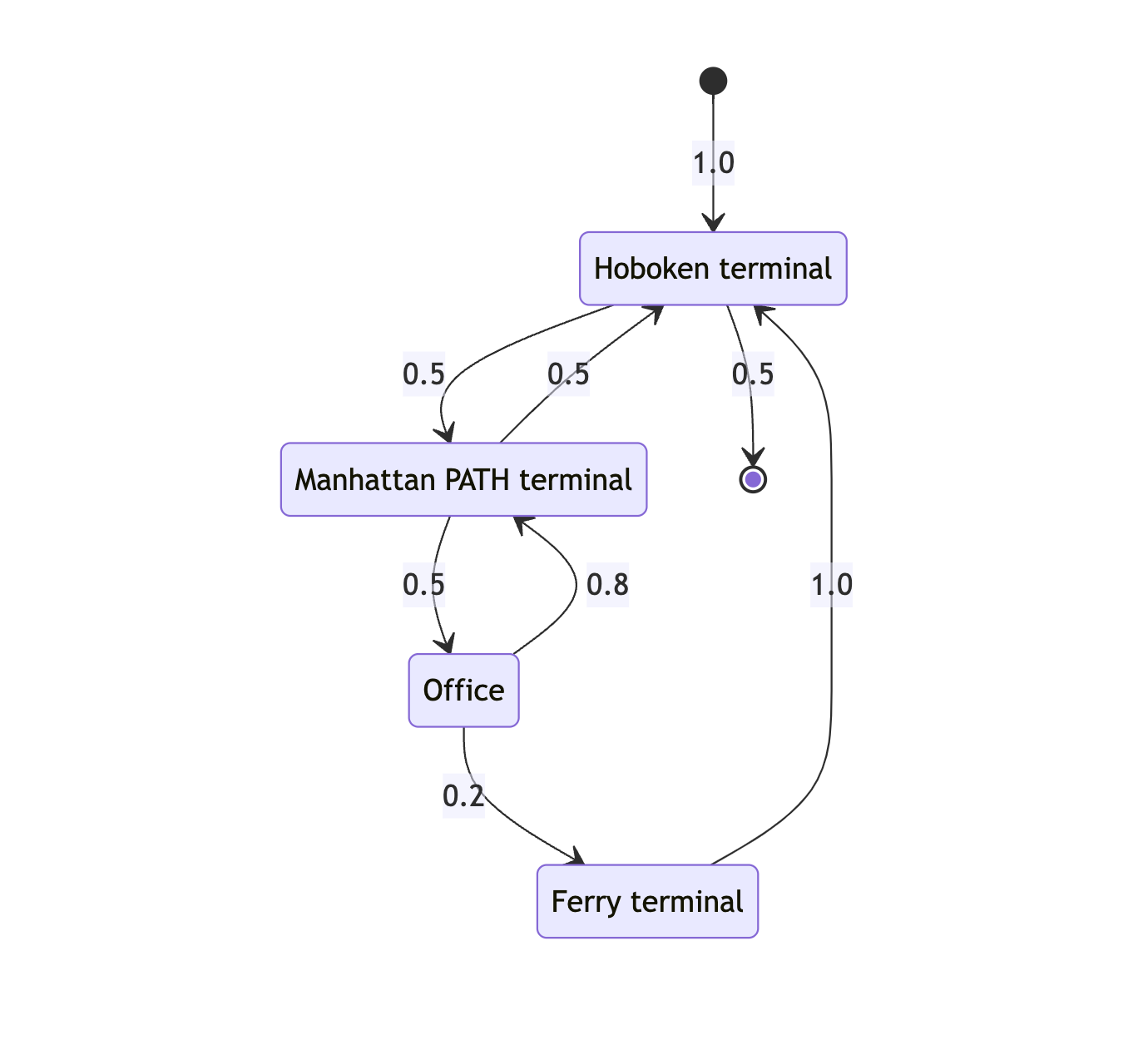
export const dailyCommute = {
START: { HobokenTerminal: 1.0 },
HobokenTerminal: {
ManhattanPATH: 0.5,
END: 0.5,
},
ManhattanPATH: {
HobokenTerminal: 0.5,
Office: 0.5,
},
Office: {
ManhattanPATH: 0.8,
FerryTerminal: 0.2,
},
FerryTerminal: {
HobokenTerminal: 1.0,
},
};{ ManhattanPath: 0.8, FerryTerminal: 0.2 }, we can write a small program to choose one of their options, keeping their weights in mind.
export function markovChoice(
candidates: Record<string, number>,
) {
const totalWeight = Object.values(
candidates,
).reduce((a, b) => a + b);
let result = null;
let rand =
Math.random() * totalWeight;
for (
let index = 0;
rand >= 0;
index++
) {
result =
Object.keys(candidates)[index];
rand -=
Object.values(candidates)[index];
}
return result;
}const { markovChoice } = await import(
"https://esm.town/v/jdan/" +
"markovChoice"
);
export function traverse(chain) {
let node = "START";
let result = [node];
while (node !== "END") {
node = markovChoice(chain[node]);
result.push(node);
}
return result;
}const { dailyCommute } = await import(
"https://esm.town/v/jdan/" +
"dailyCommute"
);
const { traverse } = await import(
"https://esm.town/v/jdan/" +
"traverse"
);
export const randomCommutes = (() => {
for (let i = 0; i < 10; i++) {
console.log(traverse(dailyCommute));
}
})();
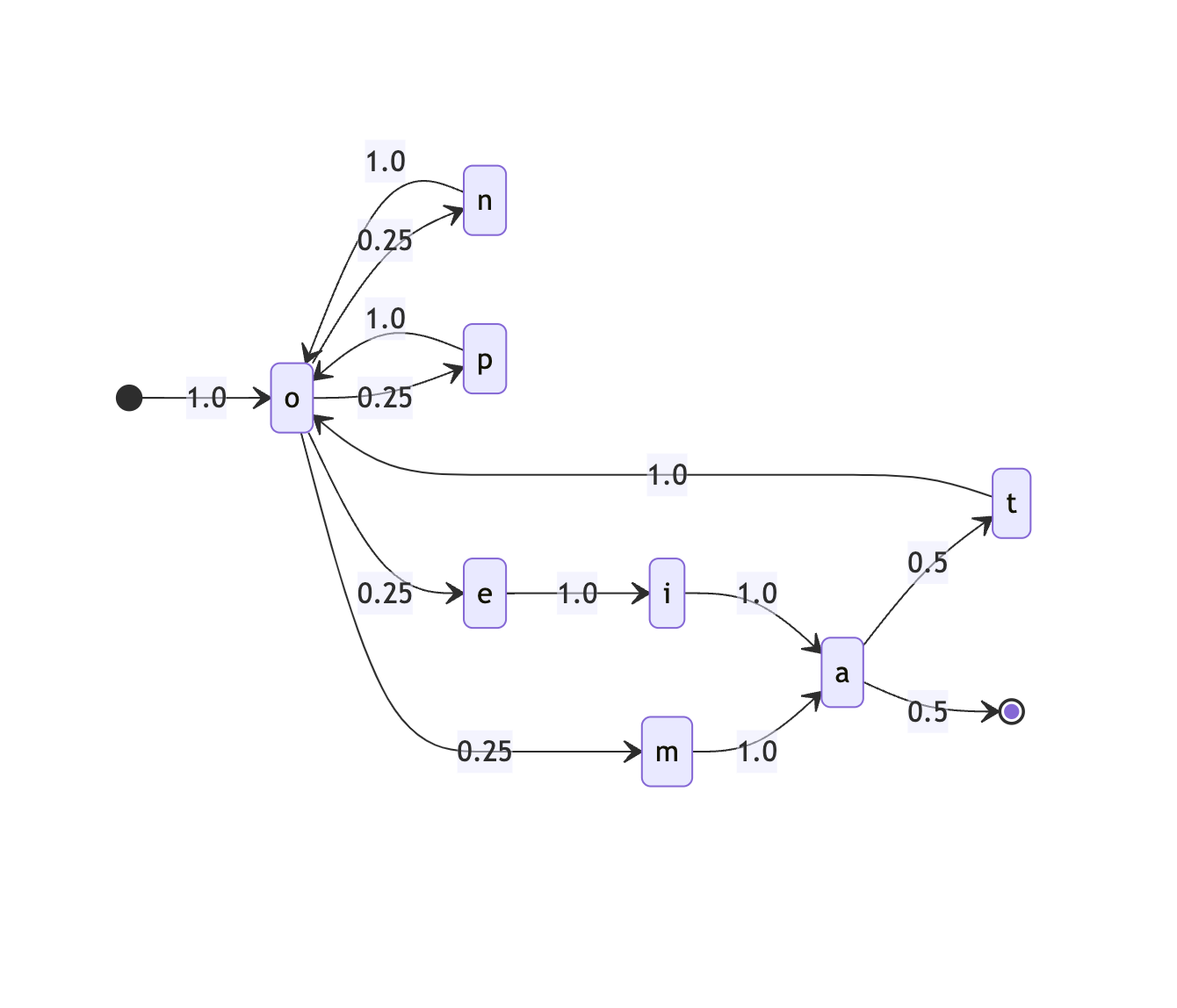
export const markovOfString = (
input,
) => {
const markov = {};
for (
let i = 0;
i < input.length;
i++
) {
const stem = input[i];
// START -->
if (i === 0) {
markov["START"] ??= {};
markov["START"][stem] ??= 0;
markov["START"][stem]++;
}
const next =
i === input.length - 1
? "END"
: input[i + 1];
markov[stem] ??= {};
markov[stem][next] ??= 0;
markov[stem][next]++;
}
return markov;
};const { markovOfString } = await import(
"https://esm.town/v/jdan/" +
"markovOfString"
);
export let onomatopoeiaMarkovChain =
markovOfString("onomatopoeia");@jdan.randomCommutes, we can generate random strings from this chain.
const { onomatopoeiaMarkovChain } =
await import(
"https://esm.town/v/jdan/" +
"onomatopoeiaMarkovChain"
);
const { traverse } = await import(
"https://esm.town/v/jdan/" +
"traverse"
);
export const randomOnomatopoeias =
(() => {
for (let i = 0; i < 10; i++) {
console.log(
traverse(
onomatopoeiaMarkovChain,
)
.slice(1, -1)
.join(""),
);
}
})();@jdan.markovOfString to operate on a list of strings, registering them on the chain one by one.
export const markovOfStrings = (
strings,
) => {
const markov = {};
//
// Loop over `strings`
strings.forEach((input) => {
for (
let i = 0;
i < input.length;
i++
) {
const stem = input[i];
// START -->
if (i === 0) {
markov["START"] ??= {};
markov["START"][stem] ??= 0;
markov["START"][stem]++;
}
const next =
i === input.length - 1
? "END"
: input[i + 1];
markov[stem] ??= {};
markov[stem][next] ??= 0;
markov[stem][next]++;
}
});
return markov;
};const { markovOfStrings } =
await import(
"https://esm.town/v/jdan/" +
"markovOfStrings"
);
export let markovOfRandomStrings =
markovOfStrings([
"onomatopoeia",
"jordan",
"programming",
"typescript",
"markov",
]);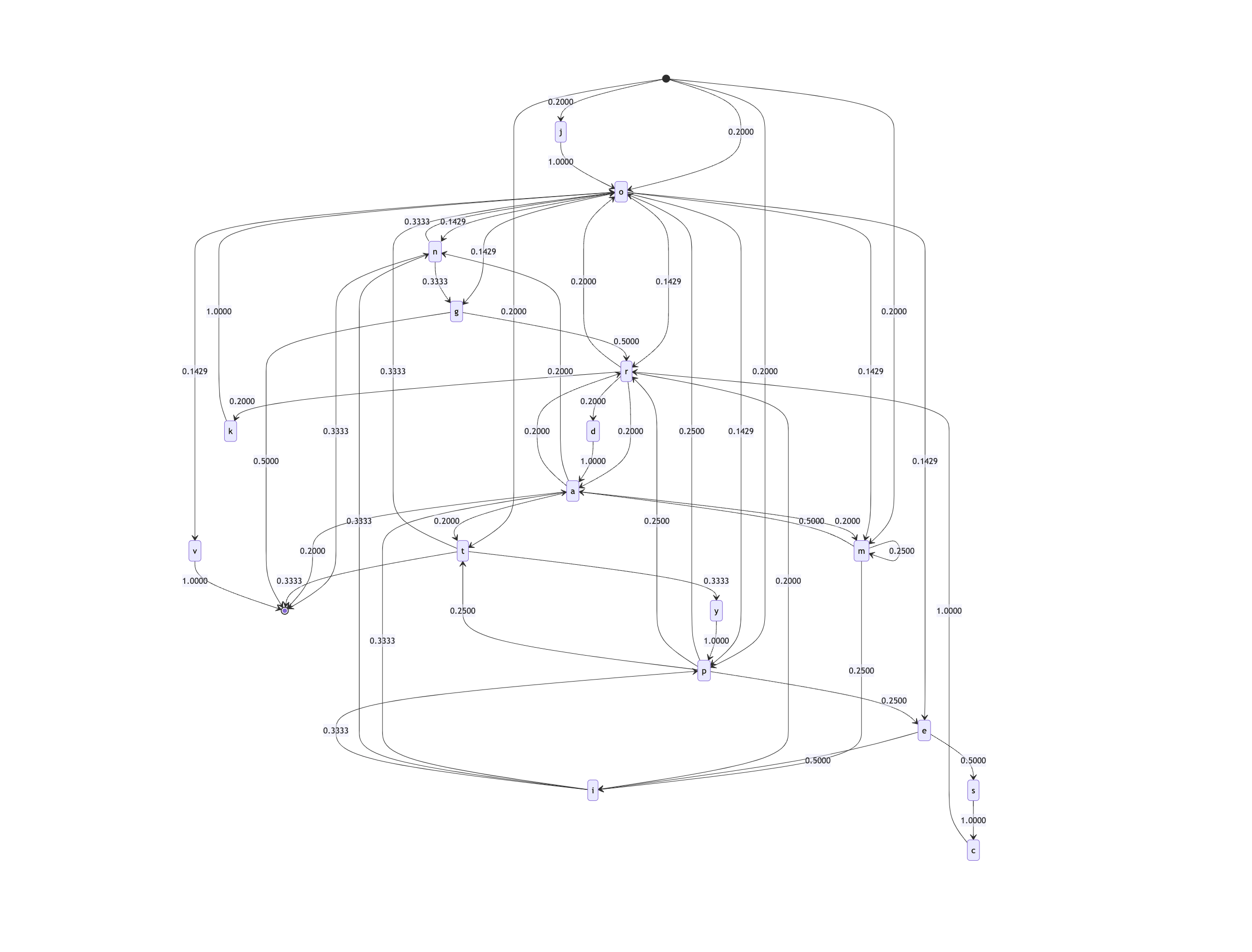
@jdan.traverse function has no problem with graphs of this size.
const { markovOfRandomStrings } =
await import(
"https://esm.town/v/jdan/" +
"markovOfRandomStrings"
);
const { traverse } = await import(
"https://esm.town/v/jdan/" +
"traverse"
);
export const randomJumbledWords =
(() => {
for (let i = 0; i < 10; i++) {
console.log(
traverse(markovOfRandomStrings)
.slice(1, -1)
.join(""),
);
}
})();$ cat /usr/share/dict/words | grep crd
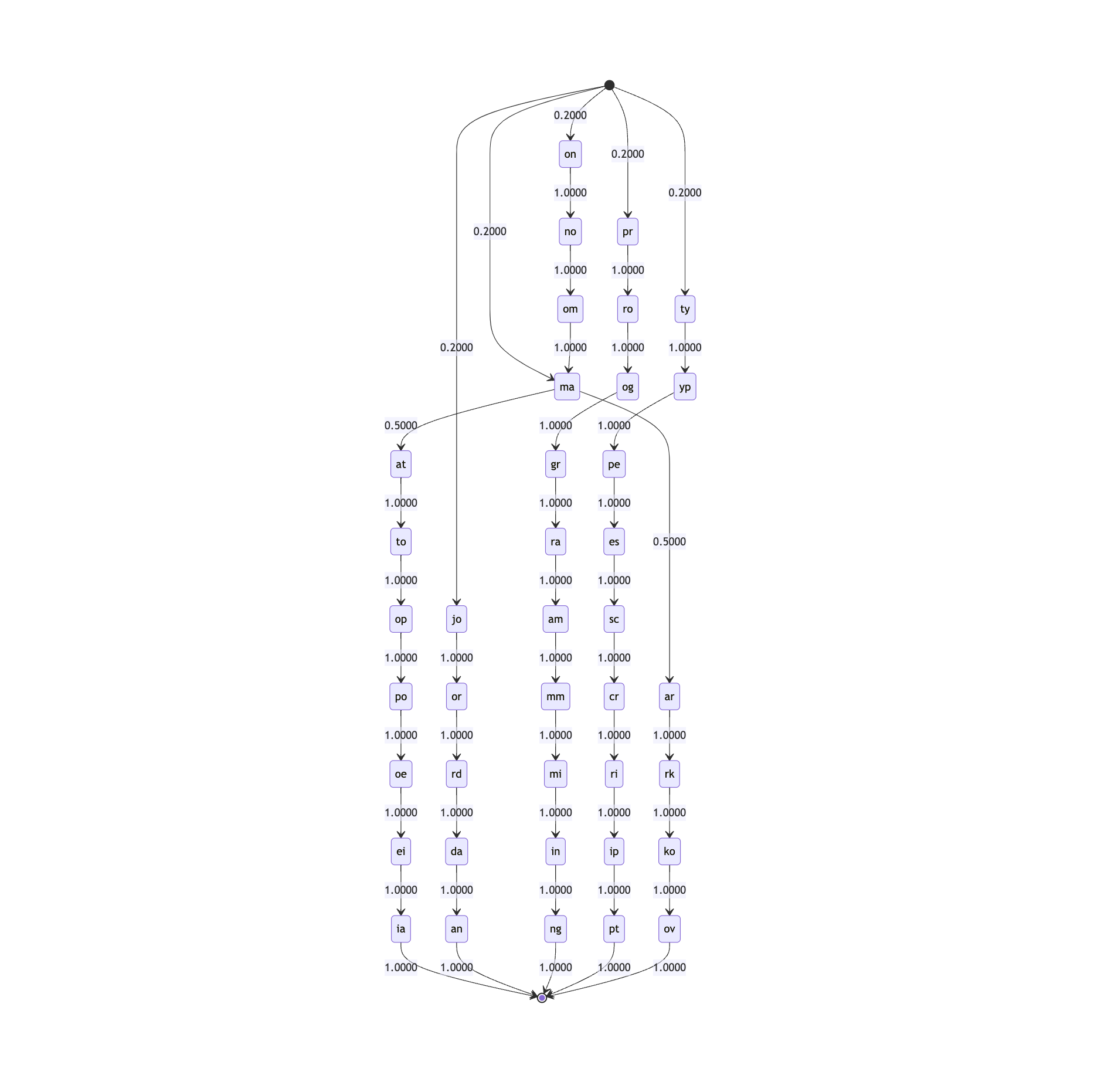
$ @jdan.markovOfStrings to accomplish this.
export const markovPairwiseOfStrings = (
strings,
) => {
const markov = {};
//
// Loop over `strings`
strings.forEach((input) => {
// Loop from the string start
// to one before the end
for (
let i = 0;
i < input.length - 1;
i++
) {
// Instead of input[i], grab
// two characters starting at i
const stem = input.slice(
i,
i + 2,
);
// START -->
if (i === 0) {
markov["START"] ??= {};
markov["START"][stem] ??= 0;
markov["START"][stem]++;
}
// Instead of input[i+1], grab
// two characters starting at i+1
const next =
i === input.length - 2
? "END"
: input.slice(i + 1, i + 3);
markov[stem] ??= {};
markov[stem][next] ??= 0;
markov[stem][next]++;
}
});
return markov;
};
const { markovPairwiseOfStrings } =
await import(
"https://esm.town/v/jdan/" +
"markovPairwiseOfStrings"
);
export let
markovPairwiseOfRandomStrings =
markovPairwiseOfStrings([
"onomatopoeia",
"jordan",
"programming",
"typescript",
"markov",
]);const { markovChoice } = await import(
"https://esm.town/v/jdan/" +
"markovChoice"
);
export function traversePairwise(
chain,
) {
let node = "START";
let result = [];
while (node !== "END") {
node = markovChoice(chain[node]);
result.push(node);
}
// 1. Trim END off the end
// 2. Take the whole two-character
// string if this is the first pass
// 3. Otherwise, take only the
// last character
return result
.slice(0, -1)
.map((word, idx) => {
if (idx === 0) {
return word;
}
return word[word.length - 1];
});
}const { traversePairwise } =
await import(
"https://esm.town/v/jdan/" +
"traversePairwise"
);
const { markovPairwiseOfStrings } =
await import(
"https://esm.town/v/jdan/" +
"markovPairwiseOfStrings"
);
export const
randomJumbledPairwiseWords =
(() => {
let markovPairwiseOfRandomStrings =
markovPairwiseOfStrings([
"onomatopoeia",
"jordan",
"programming",
"typescript",
"markov",
]);
for (let i = 0; i < 10; i++) {
console.log(
traversePairwise(
markovPairwiseOfRandomStrings,
).join(""),
);
}
})();
export const elements = [
"Hydrogen",
"Helium",
"Lithium",
"Beryllium",
"Boron",
"Carbon",
"Nitrogen",
"Oxygen",
"Fluorine",
"Neon",
"Sodium",
"Magnesium",
"Aluminum",
"Silicon",
"Phosphorus",
"Sulfur",
"Chlorine",
"Argon",
"Potassium",
"Calcium",
"Scandium",
"Titanium",
"Vanadium",
"Chromium",
"Manganese",
"Iron",
"Cobalt",
"Nickel",
"Copper",
"Zinc",
"Gallium",
"Germanium",
"Arsenic",
"Selenium",
"Bromine",
"Krypton",
"Rubidium",
"Strontium",
"Yttrium",
"Zirconium",
"Niobium",
"Molybdenum",
"Technetium",
"Ruthenium",
"Rhodium",
"Palladium",
"Silver",
"Cadmium",
"Indium",
"Tin",
"Antimony",
"Tellurium",
"Iodine",
"Xenon",
"Cesium",
"Barium",
"Lanthanum",
"Cerium",
"Praseodymium",
"Neodymium",
"Promethium",
"Samarium",
"Europium",
"Gadolinium",
"Terbium",
"Dysprosium",
"Holmium",
"Erbium",
"Thulium",
"Ytterbium",
"Lutetium",
"Hafnium",
"Tantalum",
"Tungsten",
"Rhenium",
"Osmium",
"Iridium",
"Platinum",
"Gold",
"Mercury",
"Thallium",
"Lead",
"Bismuth",
"Polonium",
"Astatine",
"Radon",
"Francium",
"Radium",
"Actinium",
"Thorium",
"Protactinium",
"Uranium",
"Neptunium",
"Plutonium",
"Americium",
"Curium",
"Berkelium",
"Californium",
"Einsteinium",
"Fermium",
"Mendelevium",
"Nobelium",
"Lawrencium",
"Rutherfordium",
"Dubnium",
"Seaborgium",
"Bohrium",
"Hassium",
"Meitnerium",
];const { elements } = await import(
"https://esm.town/v/jdan/" +
"elements"
);
const { markovPairwiseOfStrings } =
await import(
"https://esm.town/v/jdan/" +
"markovPairwiseOfStrings"
);
export const elementsMarkov =
markovPairwiseOfStrings(
elements.map((element) =>
element.toLowerCase(),
),
);
const { elementsMarkov } = await import(
"https://esm.town/v/jdan/" +
"elementsMarkov"
);
const { traversePairwise } =
await import(
"https://esm.town/v/jdan/" +
"traversePairwise"
);
export const randomElements = (() => {
for (let i = 0; i < 10; i++) {
console.log(
traversePairwise(
elementsMarkov,
).join(""),
);
}
})();