I made a piece of
hashart called
element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
values
The algorithm that generates the name of the element uses a Markov chain.
A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. Informally, this may be thought of as, "What happens next depends only on the state of affairs now.”
These are really fun data structures, relevant in the agent of LLMs, and surprisingly easy to implement. We’ll do so with a few simple code examples, but first let’s build an intuition for what these things are and how they relate to our chemical “name generation.”
I’m a creature of habit. My commute to work can roughly be summarized with the following:
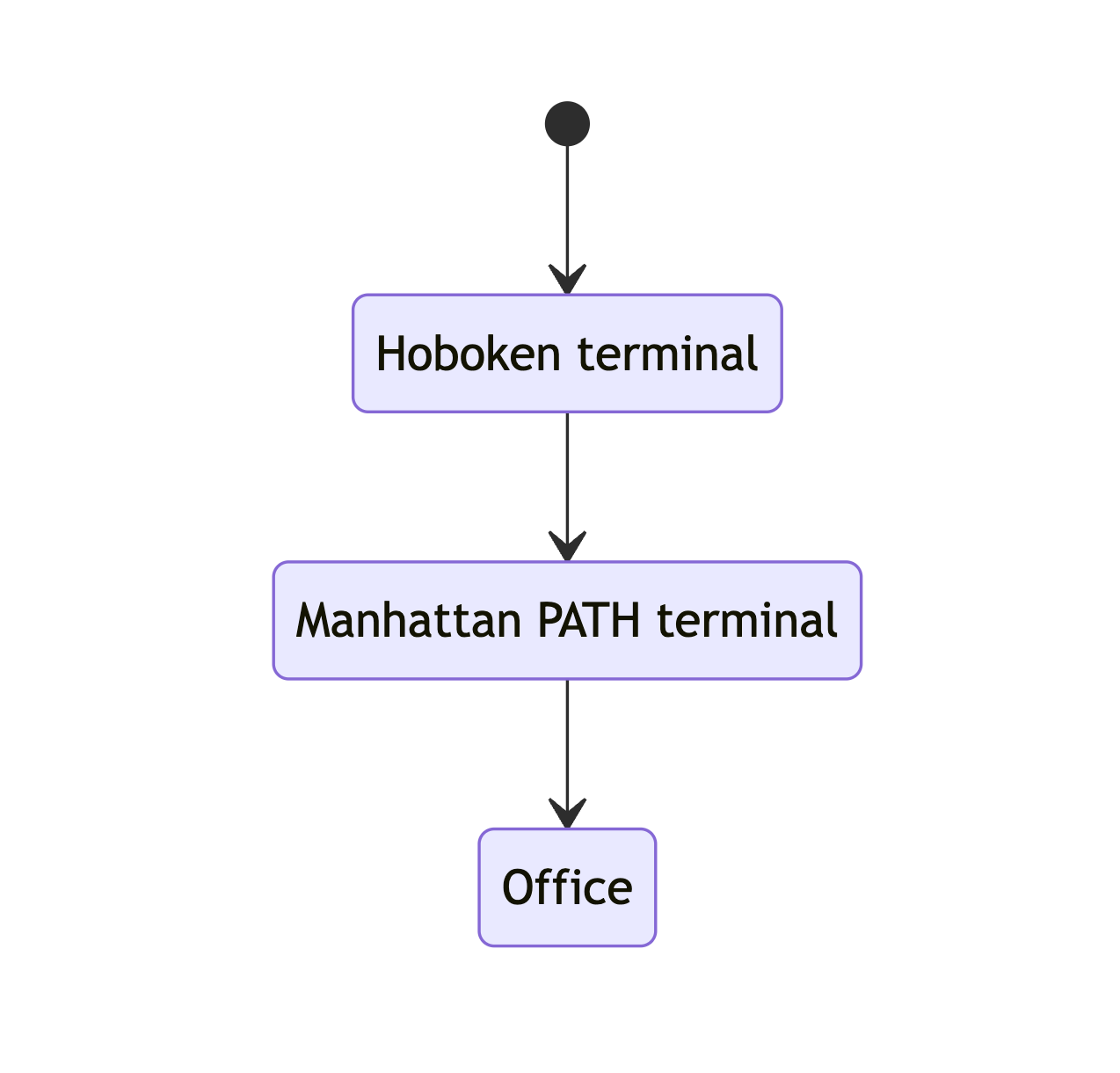
Wake up in my apartment
Walk to the Hoboken PATH terminal
Take the PATH to Manhattan
Walk to the office
We can draw a diagram showing where I currently am.
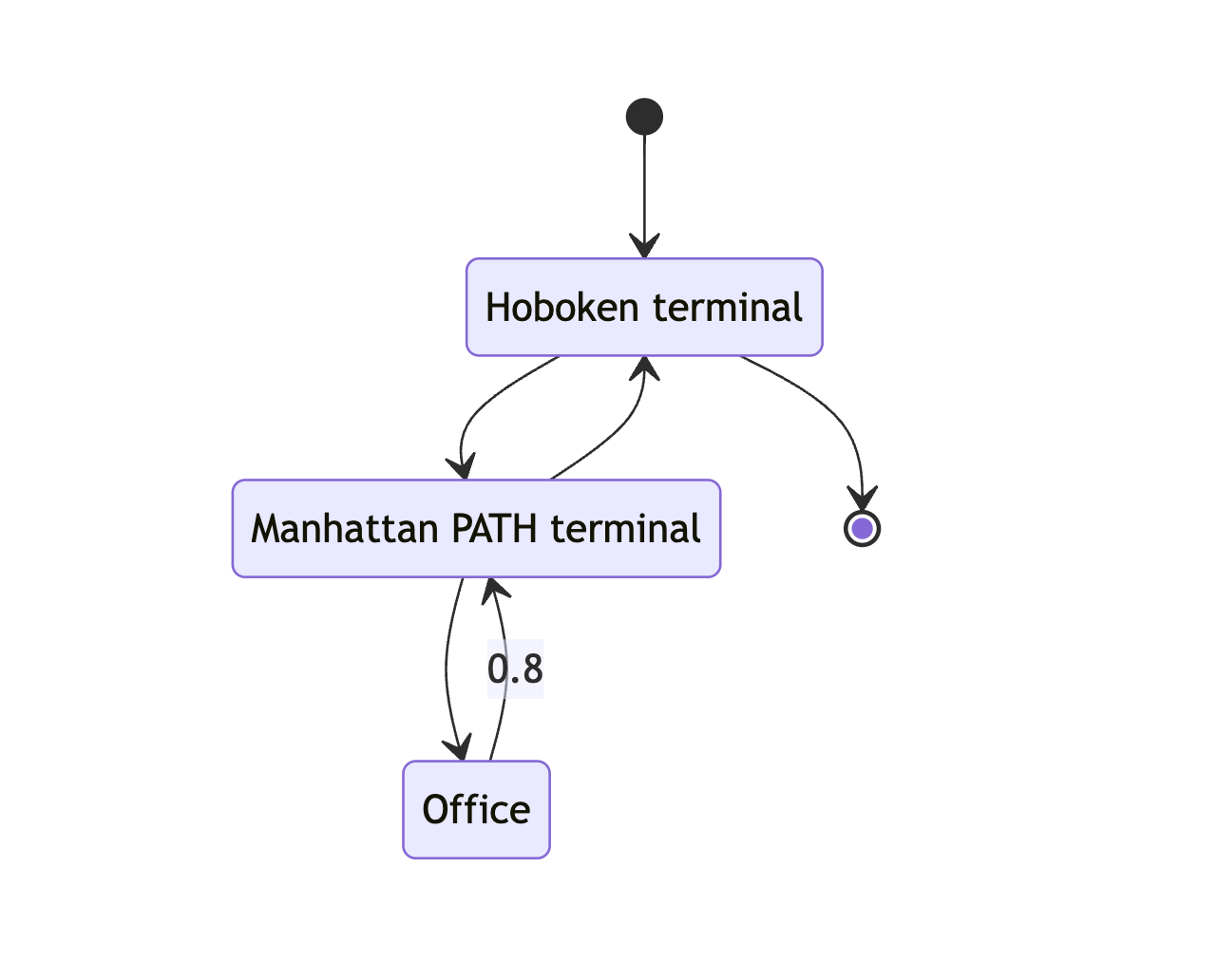
My commute home, however, has a fork in the road. 80% of the time I walk to PATH and head home. 20% of the time I take the boat . We’ll add these states and, importantly, the probabilities of each route.
Here’s the graph with my PATH commute home added. Notice a new end state. Once I’m at Hoboken PATH my commute is pretty much over.
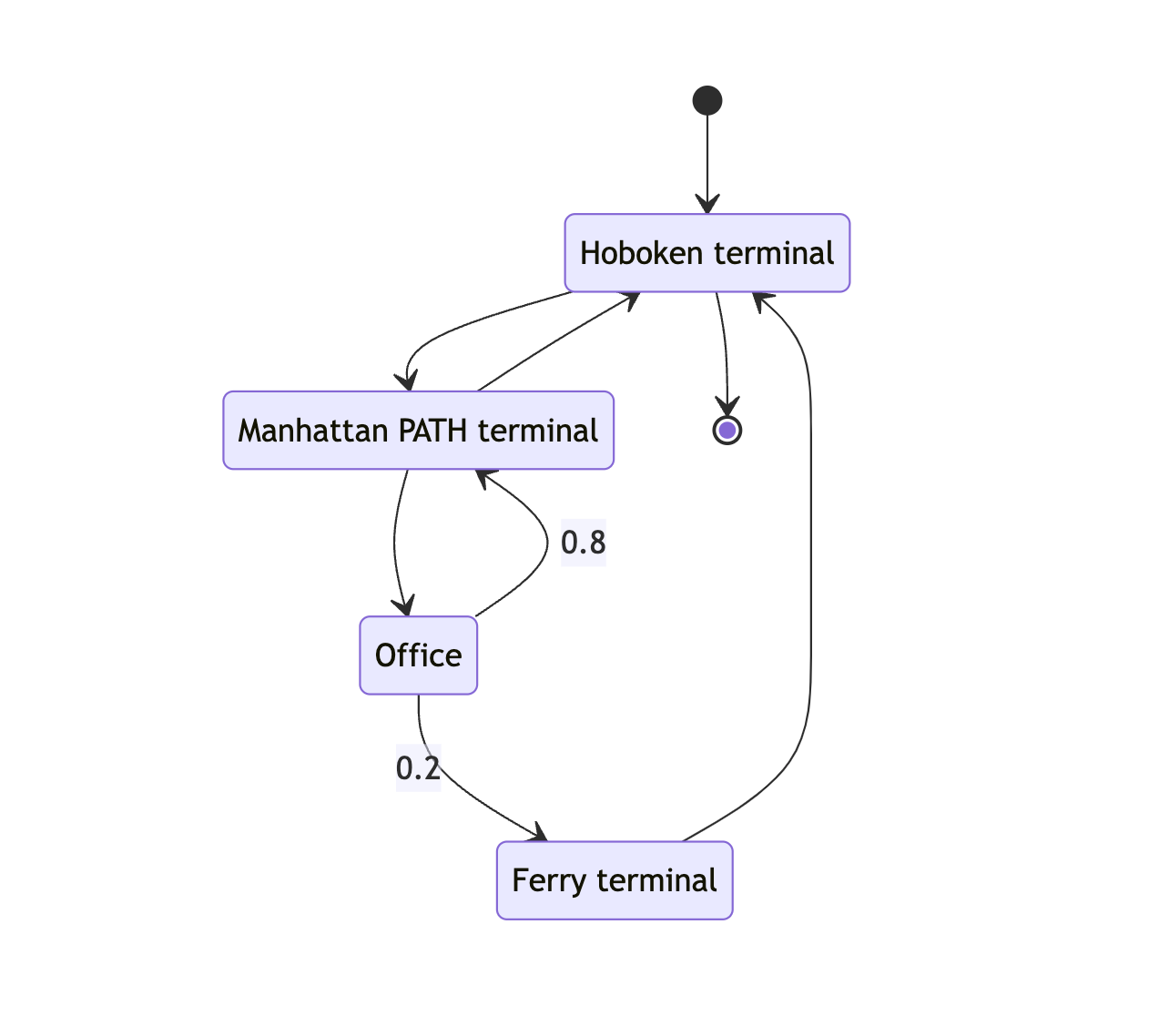
We can also introduce my boat commute.
Many of our arrows are unlabeled. For simplicity’s sake, let’s split the probabilities evenly. If two arrows come out of a box, they each get 0.5.
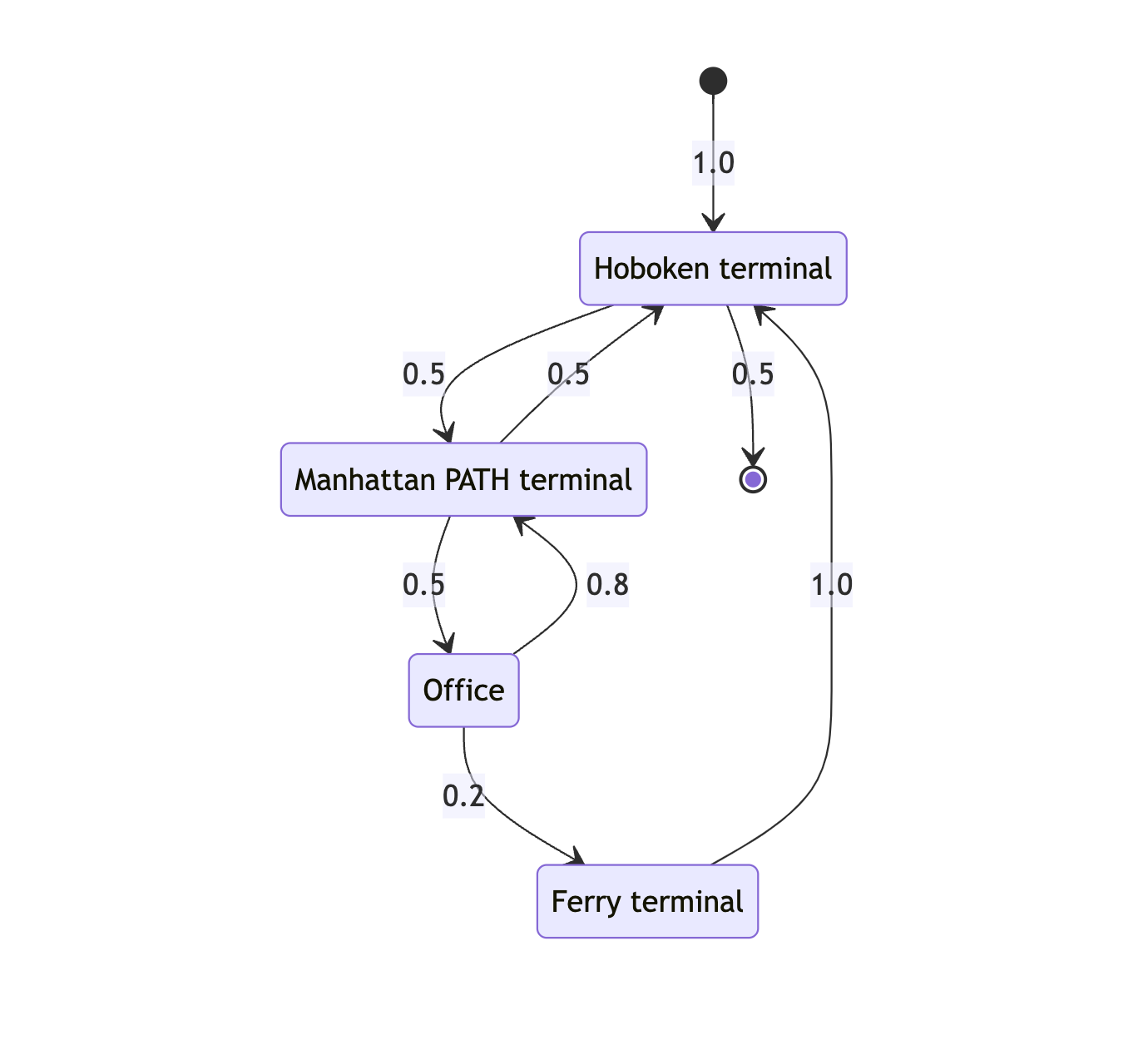
Congrats, we’ve created a Markov chain! We can look at various points in the graph and make the following observations:
Initially, I always start at Hoboken terminal.
If I’m at the office, there is an 80% chance I am headed to the PATH and a 20% chance I am headed to the Ferry.
If I’m at the Ferry terminal, there is a 100% chance I am going to Hoboken terminal.
More interesting observations also appear:
If I’m at the PATH in Manhattan, there is a 50% chance I am going to the office (morning), and a 50% chance I am going to Hoboken terminal (afternoon).
If I’m at the Hoboken terminal, there is a 50% chance I am headed to Manhattan, and a 50% chance I’m done with my commute.
Markov chains do not have any memory, and merely describe “What comes next.” If we start and keep asking “What comes next?” we can trace out some viable routes.
There are a countably infinite number of paths my simple commute devolves too, using nothing but the power of probability and forgetting where you came from. Let’s code up some examples.
Here’s my daily commute, represented as a graph on
Val Town.
Given an object like { ManhattanPath: 0.8, FerryTerminal: 0.2 }, we can write a small program to choose one of their options, keeping their weights in mind.
Then, repeatedly call this program while traversing our commute graph, starting from START, and stopping once we reach END.
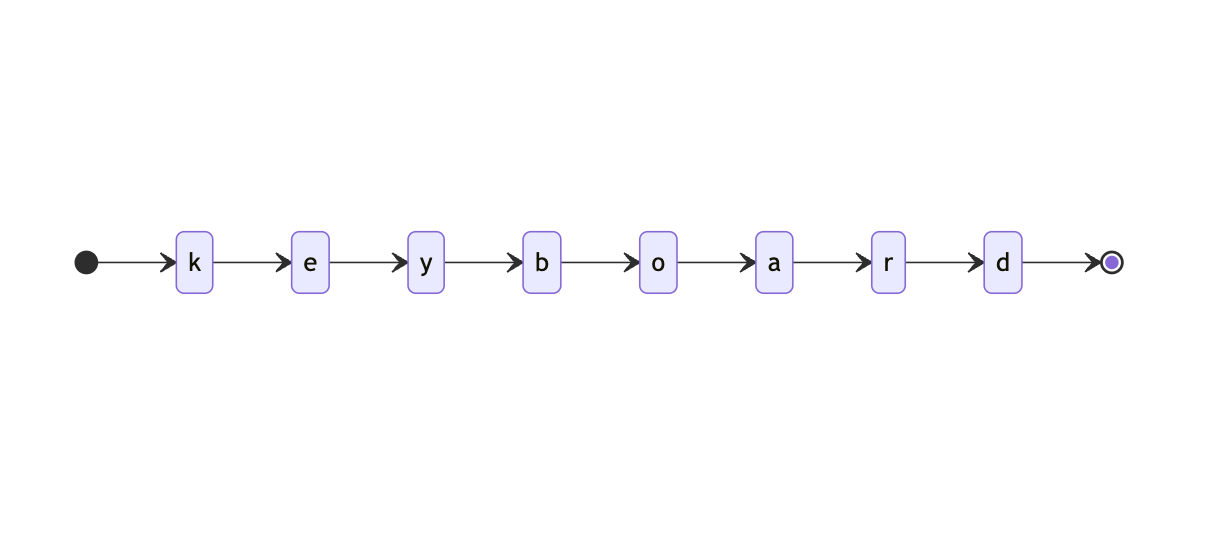
Consider the word “keyboard.” We can divide this into a list of letters.
k, e, y, b, o, a, r, d
Then, we can represent these as steps just as we did for our commute. Rather than “after the ferry we arrive at Hoboken terminal” we can say “After e we arrive at y”
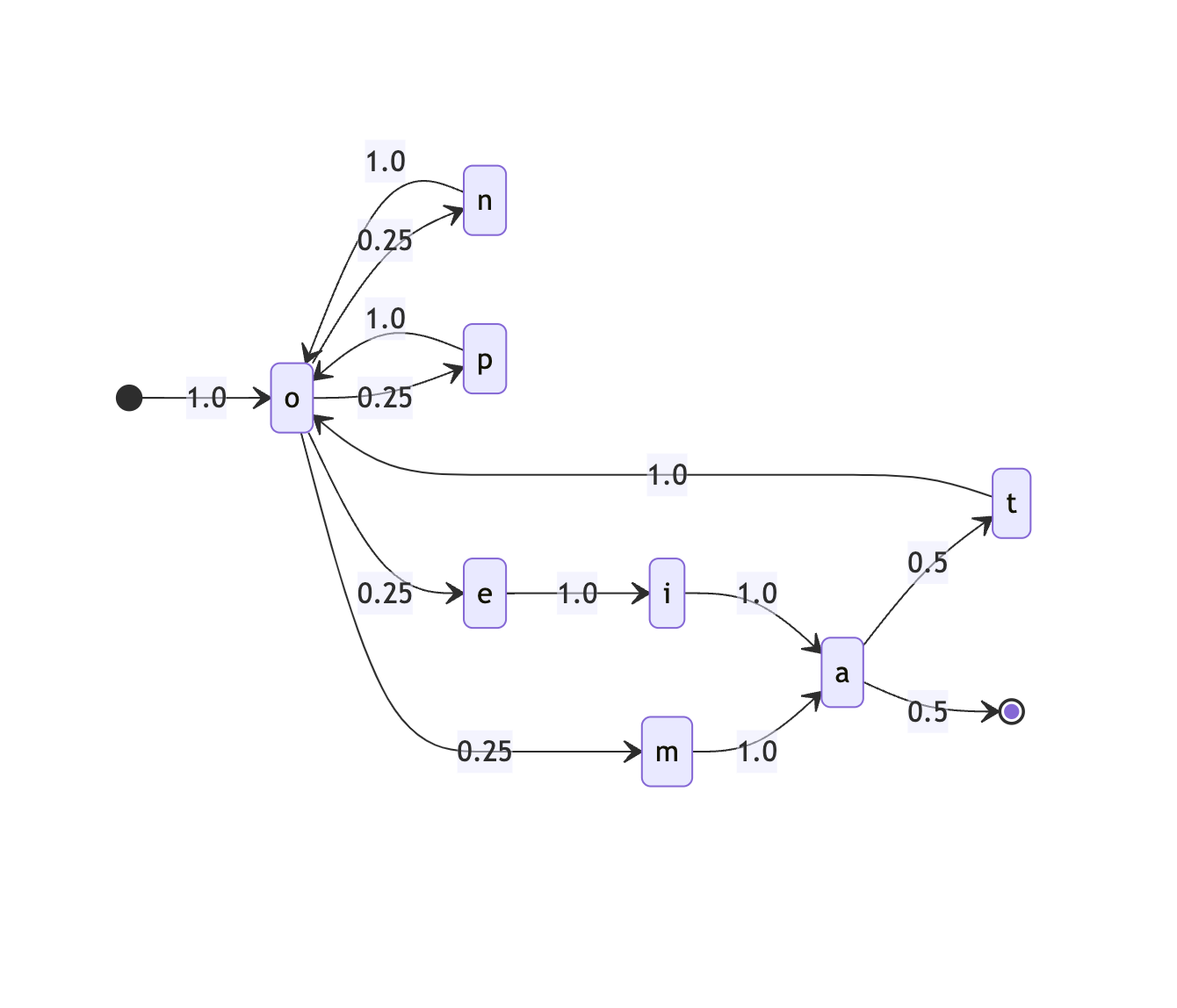
More interesting things happen if we choose a word like “onomatopoeia,” where from a given letter there are multiple next letters (just as from the Office we could go to the PATH or Ferry terminal).
To build this graph we’ll go letter by letter, but scan the rest of the string to see which letters appear next. We can see how o goes to n, m, p, and e with equal probability.
Let’s write a TypeScript program to do this for us. For simplicity’s sake we won’t keep track of percentages that add up to 1.0, but instead increment a number for each connected letter. (We could do some post-processing if we wanted to)
And we can use this to generate the markov chain for our string “onomatopoeia”
Just as we did with @jdan.randomCommutes, we can generate random strings from this chain.
While these words might be fun to try and pronounce and share some of the same characters as the source word, generating “words that look like onomatopoeia” is not particularly useful. After all, our random element above doesn’t always look like Hydrogen - it looks any of the elements on the periodic table!
To do better, we’ll need more words. We can modify @jdan.markovOfString to operate on a list of strings, registering them on the chain one by one.
Now let’s generate a chain from several different words.
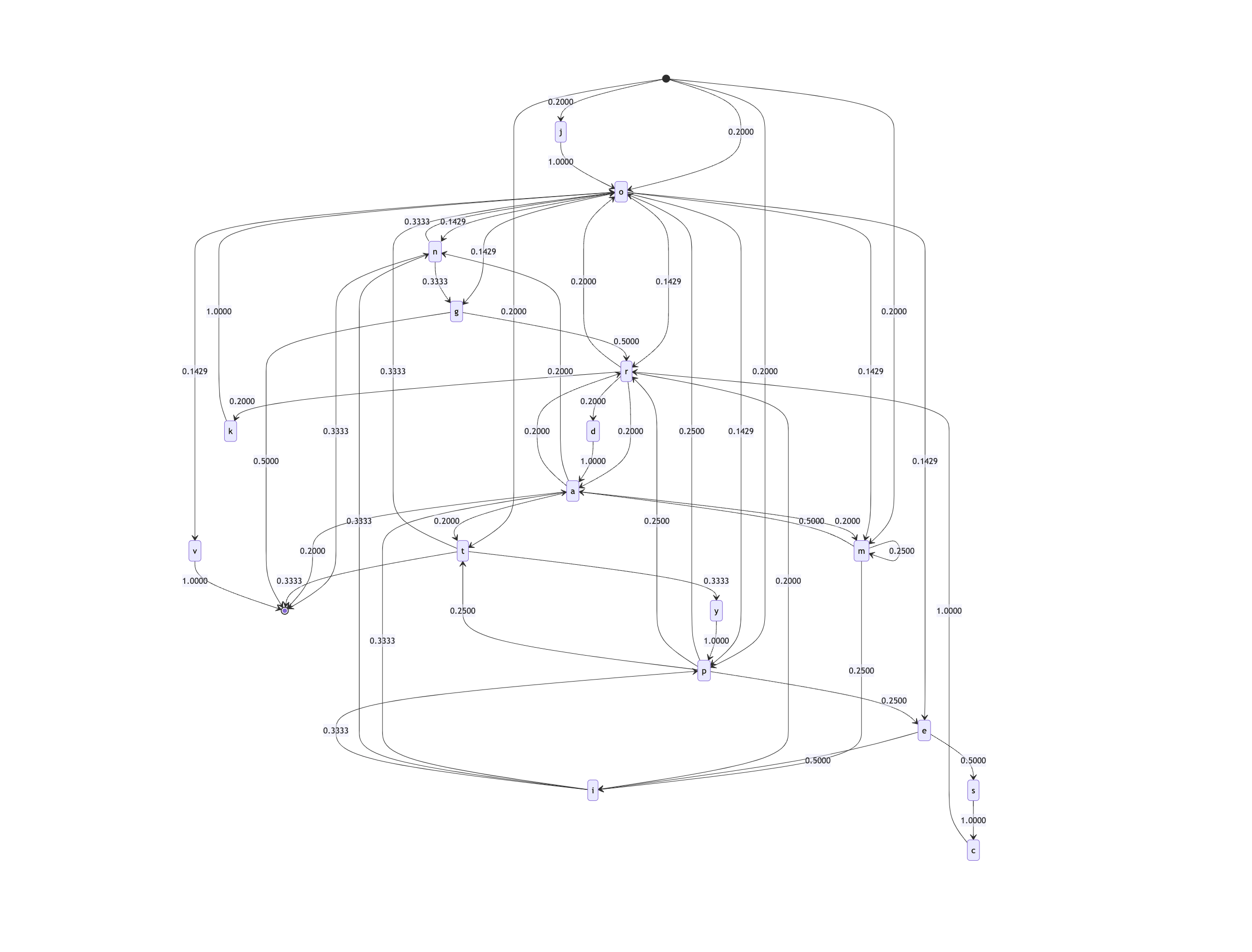
These graphs become harder and harder to visualize as the nodes (letters) and edges (transitions) grow.
Fortunately, our @jdan.traverse function has no problem with graphs of this size.
But the output is… questionable. When we look at a word like mipeipoescrdamaratypescrin, we can find a sequence of letters crd. This is valid on our chain because there is an r which comes after a c, and a d which comes after an r, but the trigramcrd is… nonsense.
$ cat /usr/share/dict/words |grep crd
$
It would be useful to tell our markov chain about these groups-of-three. In particular, for “programming” we can signal that gra is valid because a gr (bigram) is followed by an ra (bigram).
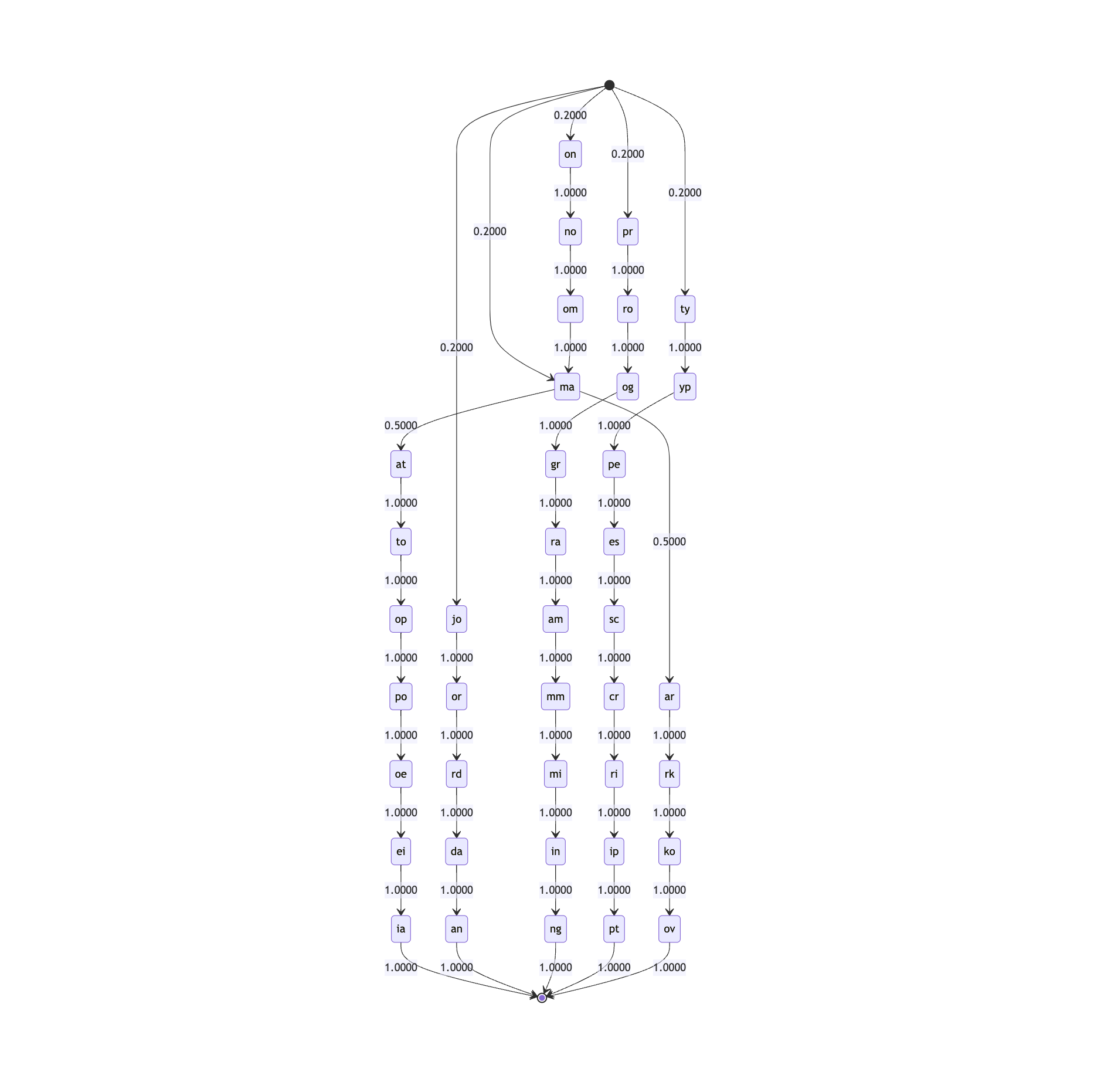
Rather than scanning one letter at a time, we can for subsequent pairs of letters. We can make slight tweaks to @jdan.markovOfStrings to accomplish this.
Which, for the same input words, produces a markov chain with a much… “tamer” feel.
Traversing this chain requires some tweaks as well, since for the transition START → pr we want to keep the entire pr, but for pr → ro we only want the o. (A classic off-by-one error!)
And now when we generate 10 words…
We certainly have more realistic looking words, but nearly all of them are in the training set! By changing letter-by-letter to pair-by-pair, we drastically cut down the noise but left only a few valid paths in the graph.
How can we fix this? We can add more words to the set!
We can ask our dear friend GPT-3 for the chemical elements.
From this array of 109 elements (quite outdated! At the time of writing this in September 2023 there are 118 known elements), we can generate a Markov chain of letter pairs (or bigrams).
Which produces a graph so gnarly it’s quite difficult to visualize.
…But easy to probe. Let’s generate some elements from it.
Giving us elements such as Flutom, Boridium, and Antimonioberbium.
Just as we plotted “Where is Jordan in his commute?” as a series of states and probabilities between them, we can outline the transitions between letters in a set of words. This turns out to be quite chaotic – producing truly nonsense strings just as we produce truly nonsense commutes (who gets off the boat and gets right back on? ).
We can tame the madness by mapping out relationship between pairs of letters, or bigrams, sacrificing uniqueness. We can then balance things out by adding many more words to the training set (such as the 109 chemical elements known to GPT-3).
The result are words that are completely made up, but sound reasonable, what more could you ask for?
I hope this post was a gentle introduction to state diagrams and the magic behind Markov chains. Here are few questions to ask yourself with your newfound knowledge:
Instead of pairs of letters, what if we map the transitions between trigrams? four-grams and five-grams? How realistic do our chemical elements sound, and how random are they?
Perhaps 109 elements isn’t enough, what if we built a Markov chain of popular English baby names? Similar to the above, how many letters do we need to use for each node in the chain for them to sound “reasonable”?
What if we didn’t start at START but at the node of our choice? What abilities could that unlock for us?
Instead of letters, what if we map out transitions between words. Can you generate poems using such a chain?
 hashart called
hashart called
 element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.
element. It allows you to generate realistic sounding chemical elements from a seed phrase - the same phrase always gives you the same element.

 . We’ll add these states and, importantly, the probabilities of each route.
. We’ll add these states and, importantly, the probabilities of each route.
 end state. Once I’m at Hoboken PATH my commute is pretty much over.
end state. Once I’m at Hoboken PATH my commute is pretty much over.
 → Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →
→ Hoboken terminal → Manhattan PATH → Office → Manhattan PATH → Hoboken terminal →